Comprender cómo funciona el rastreo y, sobre todo, aprender a controlarlo, no es un detalle técnico más. Es un acto de estrategia. Es como decidir qué puertas abrir y cuáles mantener cerradas en una ciudad llena de visitantes.
El arte del rastreo: cómo los motores encuentran tu web
El rastreo funciona gracias a los famosos bots o arañas (spiders), que se mueven de enlace en enlace como si fueran viajeros saltando de estación en estación.
- Cada enlace interno es como un pasillo que conecta habitaciones dentro de tu propia casa digital.
- Cada enlace externo es como un puente que une tu ciudad con el resto del mundo online.
Cuando Googlebot llega a tu web, no solo registra la página que visita, sino que utiliza cada link como una invitación a explorar más a fondo. Cuantos más caminos claros y accesibles encuentre, mejor podrá entender la lógica y jerarquía de tu sitio.
El control del acceso: abrir o cerrar puertas estratégicamente
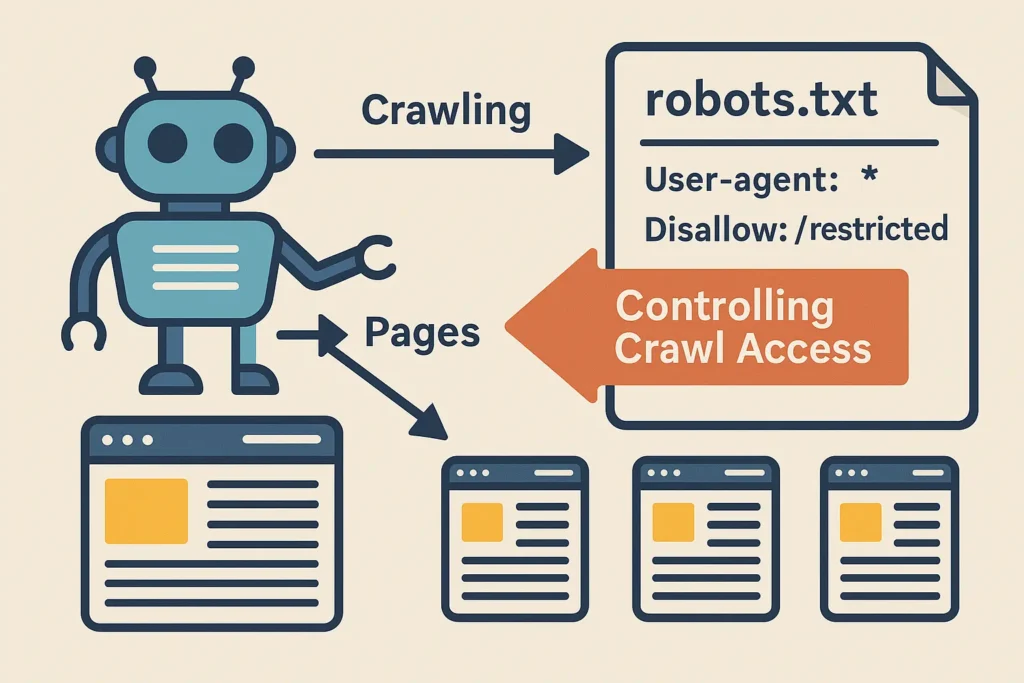
Aquí es donde entra en juego un archivo que parece insignificante pero que tiene un poder monumental: el robots.txt.
Este archivo, alojado en la raíz de tu dominio, es como la constitución digital de tu web. Le indica a los bots qué zonas son públicas, cuáles son privadas y qué caminos no deberían seguir.
Con él puedes:
- Bloquear secciones innecesarias: como páginas de login, tests A/B o entornos de staging.
- Ahorrar recursos: evitar que los bots gasten energía rastreando contenido irrelevante o duplicado.
- Guiar la atención: dirigir a los buscadores hacia lo que realmente quieres que indexen y rankeen.
En otras palabras, el robots.txt no se trata solo de prohibir, sino de curar la experiencia de rastreo para que tu web sea interpretada en su mejor versión.
Robots.txt en acción: ejemplos estratégicos
- Escenario 1: rediseño en progreso
Tienes una versión beta de tu web en un subdominio (staging.tusitio.com). Con un simpleDisallow: /en ese entorno, evitas que Google muestre al mundo algo inacabado. - Escenario 2: contenido duplicado
Si manejas variaciones de productos con múltiples URLs, puedes bloquear los duplicados para que solo la versión canónica sea rastreada. - Escenario 3: priorización de recursos
Un e-commerce con miles de páginas no necesita que los bots visiten a diario la sección de “términos y condiciones”. Con un ajuste en robots.txt, concentras el rastreo en fichas de productos y categorías clave.
¿Por qué todo esto importa tanto?
El rastreo no es infinito. Google asigna a cada web un presupuesto de rastreo (crawl budget). Si tus bots malgastan ese tiempo revisando páginas inútiles, es probable que tus secciones críticas no se rastreen con la frecuencia adecuada.
Aquí está lo disruptivo: controlar el rastreo no es censurar, es dirigir. Al igual que un director de orquesta no toca todos los instrumentos a la vez, sino que decide qué debe sonar y cuándo, tú decides qué partes de tu web merecen la atención inmediata de los motores de búsqueda.
El equilibrio perfecto: accesibilidad y estrategia
No se trata de bloquear a ciegas ni de abrir todo sin pensar. La clave está en encontrar el punto medio:
- Lo suficiente abierto para ser visible y relevante.
- Lo suficientemente controlado para ser eficiente y preciso.
Ese equilibrio convierte al rastreo en una ventaja competitiva: mientras otros dejan que Google interprete su web a su manera, tú defines cómo quieres que la lea.
Monitoreo Actividad de Rastreo

Qué es el SEO Técnico: El Lenguaje Secreto entre tu Web y los Motores de Búsqueda

SEO Técnico: La Arquitectura Invisible que Define tu Éxito Digital

SEO técnico mejores prácticas
Qué es el SEO técnico
